

If you’re running a DeFi operation in 2026, you know the stack: Nansen, DefiLlama, Revert Finance, Gauntlet, Telegram alerts.
But none of them work together proactively at DeFi speed. Especially when your strategy can’t leave your own infrastructure.
This is the gap a mid-size institutional liquidity fund came to us with — managing $5M+ in active positions across Ethereum, Arbitrum, Base, and Solana.
Experienced team, solid strategy, reasonable tooling for their stage.
But their setup had a structural problem that no combination of existing platforms was solving.
Every tool showed them what had already happened, but none of them connected the dots — or told them what to do next.
They were monitoring everything – but couldn’t act fast enough
When we mapped their workflow in detail, the pattern became clear.
IL alerts fired after the anomaly was already confirmed publicly.
Finding yield opportunities across chains meant manually comparing data from tools that had no connection to each other.
The core problem: every tool they had was built to show data. None of them were built to connect it — or to act on it across all positions at once.
The rebalancing window closes faster than any monitoring dashboard refreshes.
According to a 1inch report, 83 to 95% of liquidity in major DeFi pools sits idle, and 50% of retail LPs are losing money due to impermanent loss.
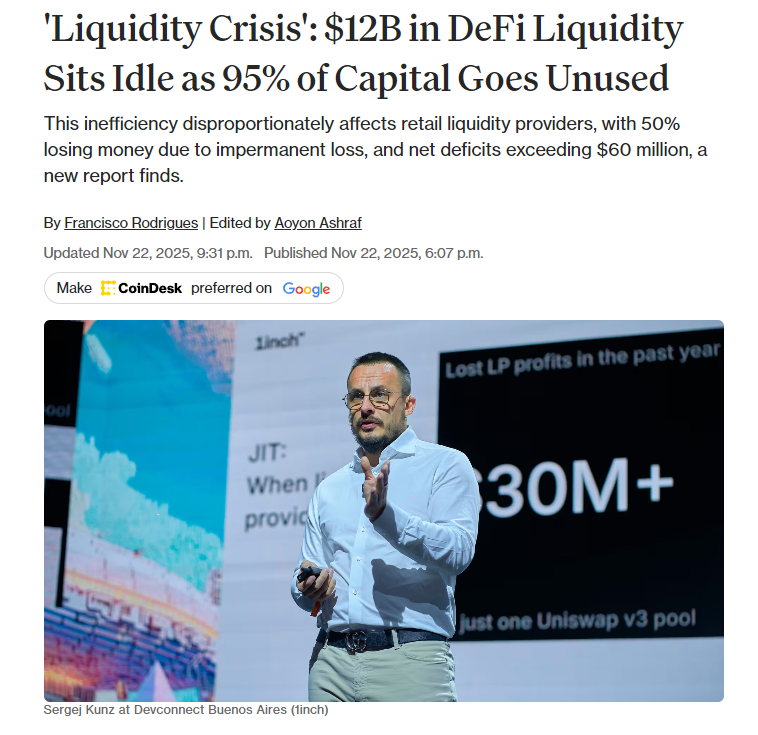
The infrastructure gap isn’t theoretical — it shows up directly in P&L, and most teams are absorbing the cost without naming it precisely.
The honest framing is this: the market has plenty of tools that tell you what is happening.
What it doesn’t have — is a system that tells you what to do next, before the window closes.
Platforms like Gauntlet and Gelato address parts of this, but both operate as external SaaS infrastructure — your position data, capital flows, and strategy logic pass through their systems.
For a fund where alpha is the core asset, that architecture doesn’t work.
There was a second constraint that came up early in the conversation and shaped every architectural decision that followed.
Their alpha could not leave their infrastructure under any circumstances.
No OpenAI API calls.
No third-party model providers processing position data, yield logic, or rebalancing signals.
This wasn’t a preference — it was a hard line, and a completely reasonable one.
In 2025, over $3.4 billion was stolen from crypto operations (Chainalysis report), with a sharp increase in attacks targeting infrastructure and third-party dependencies.
This makes the move to local, private systems mandatory: processing your strategy via external APIs is now a critical operational risk.
That’s why from day one, the entire system was designed for private cloud deployment with a local LLM running inside their own infrastructure — zero data leaving their own environment, no exceptions.
A note on the visuals in this article: the interface screenshots shown are illustrative concept representations. Per NDA, no screens from the live production system are shared. The actual deployment runs fully on-premise within the client’s private infrastructure.
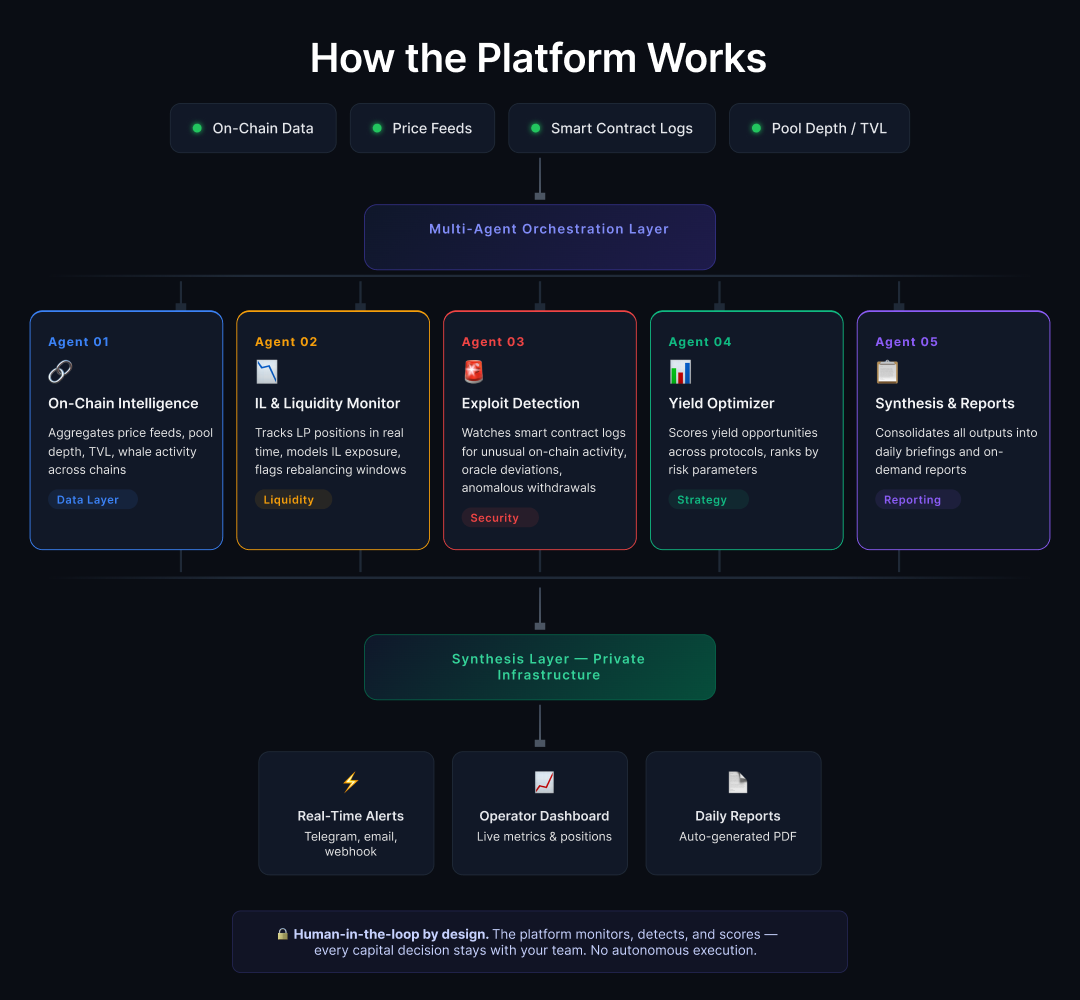
Why 5 agents instead of 1
The most common mistake we see when teams approach AI systems is building one large general-purpose model and expecting it to handle everything — monitoring, risk detection, yield optimization, reporting — all at once.
The logic sounds reasonable: one system, one interface, simpler to maintain.
In practice, constant context-switching between entirely different domains degrades output quality across all of them.
A model simultaneously watching for oracle deviations and scoring yield opportunities against risk parameters does neither job as well as a model that only does one.
Narrower scope produces sharper outputs, and in DeFi where you need precise actionable signals rather than general commentary, sharpness is the whole point.
So we split the workload across five specialized agents, each owning one domain completely.
Agent 1 — The data layer everything else runs on
The first agent is the data foundation — everything else builds on top of it.
It pulls real-time feeds across all four chains: price data, pool depth, TVL movements, gas conditions, whale wallet activity.
The real technical challenge at this layer was normalization.
Ethereum, Arbitrum, Base, and Solana each have their own data structures, their own event formats, their own quirks. Turning that into one consistent signal layer that four other agents can consume without translation overhead took a significant portion of the architecture work.
Once that normalization layer was stable, the reliability of every downstream agent improved substantially — because they were all working from the same clean, consistent input instead of pulling from fragmented sources independently.
Agent 2 — Catching impermanent loss before it locks in
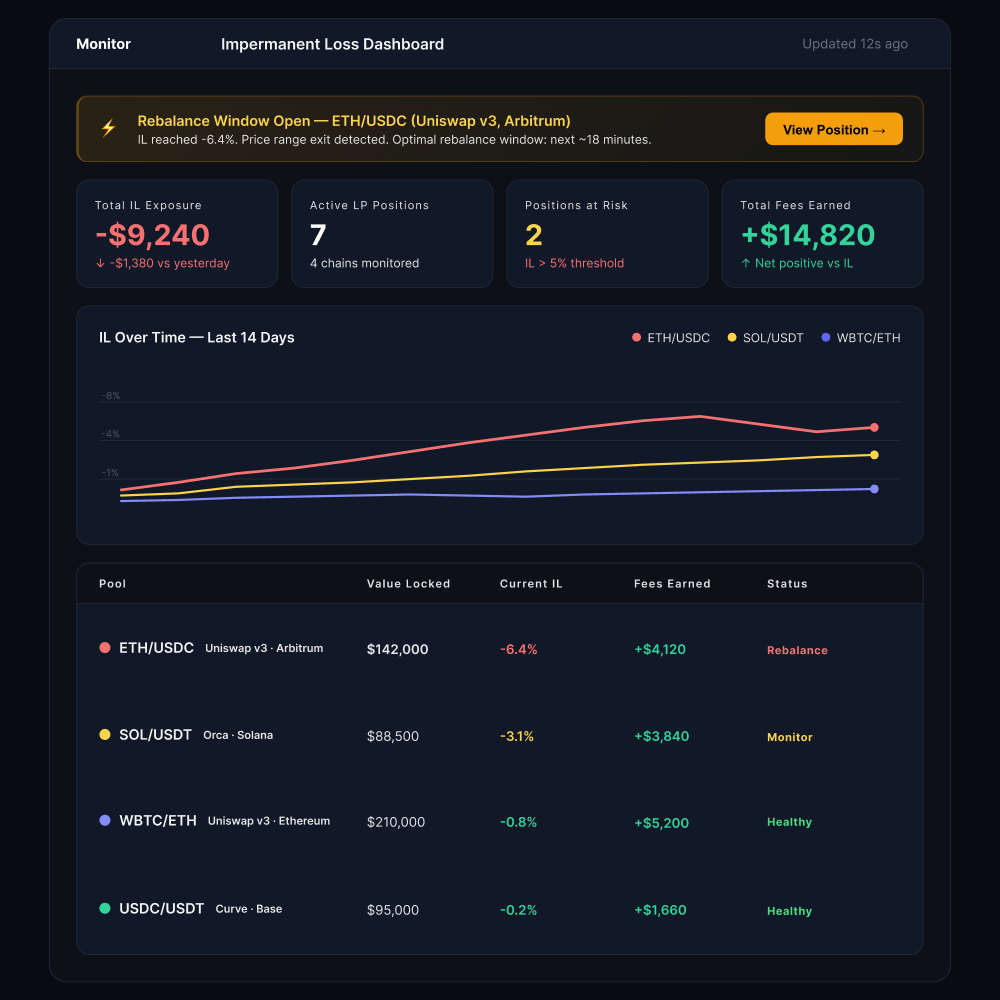
The second agent handles impermanent loss and liquidity monitoring across all active LP positions.
The distinction from standard IL tracking tools matters here: it doesn’t just track IL, it models price scenarios continuously. This flags rebalancing opportunities before losses compound, not after a manual dashboard refresh.
As mentioned earlier, over half of Uniswap V3 LPs in volatile pairs lose money specifically because of impermanent loss.
The agent’s job is to collapse the reaction window from hours down to minutes, which is the difference between a recoverable position and a locked loss.
Agent 3 — Exploit detection at block speed
The third agent handles protocol risk and exploit detection.
It watches smart contract event logs continuously for patterns that suggest something is wrong:
- unexpected large withdrawals,
- oracle price deviations,
- flash loan activity that doesn’t match normal behavior for the protocol.
The target was alerts firing within seconds of an anomaly appearing on-chain — not minutes, not after the news cycle picks it up.
Getting there required real calibration work.
A false positive rate that’s too high creates an alert system the team stops trusting, which defeats the entire purpose.
It took several weeks of live operation with real data before the signal quality reached the level where the team acted on alerts immediately rather than verifying them manually first.
For context: Forta Network’s threat data shows monitoring can flag suspicious contract interactions 18+ hours before exploits become public knowledge.
The capability exists.
The only question is: is your team using it?
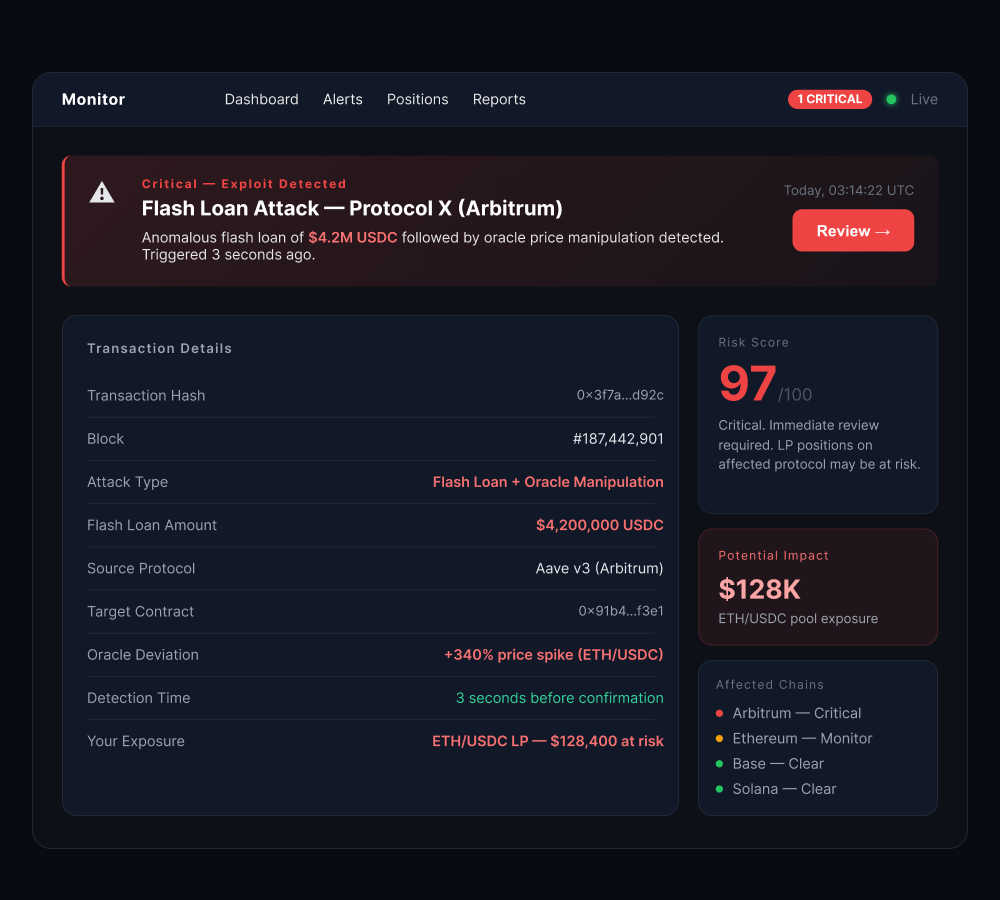
Agent 4 — Yield scoring without the manual cross-referencing
The fourth agent handles yield strategy.
It scans opportunities across protocols and chains continuously, scores each one against the fund’s current risk parameters and market conditions, and surfaces ranked recommendations.
The design principle was explicit from the start: the agent recommends, the team decides.
Every action involving capital stays with the humans.
DWF Ventures published findings in April 2026 showing that AI agents outperform humans in yield optimization in narrow, well-defined use cases — and this is precisely one of those cases.
The agent sees more protocols, more chains, and more data points simultaneously than any analyst can track manually. But autonomous execution on large positions introduces a category of risk no platform should take on behalf of a client, so we didn’t build that, and we wouldn’t.
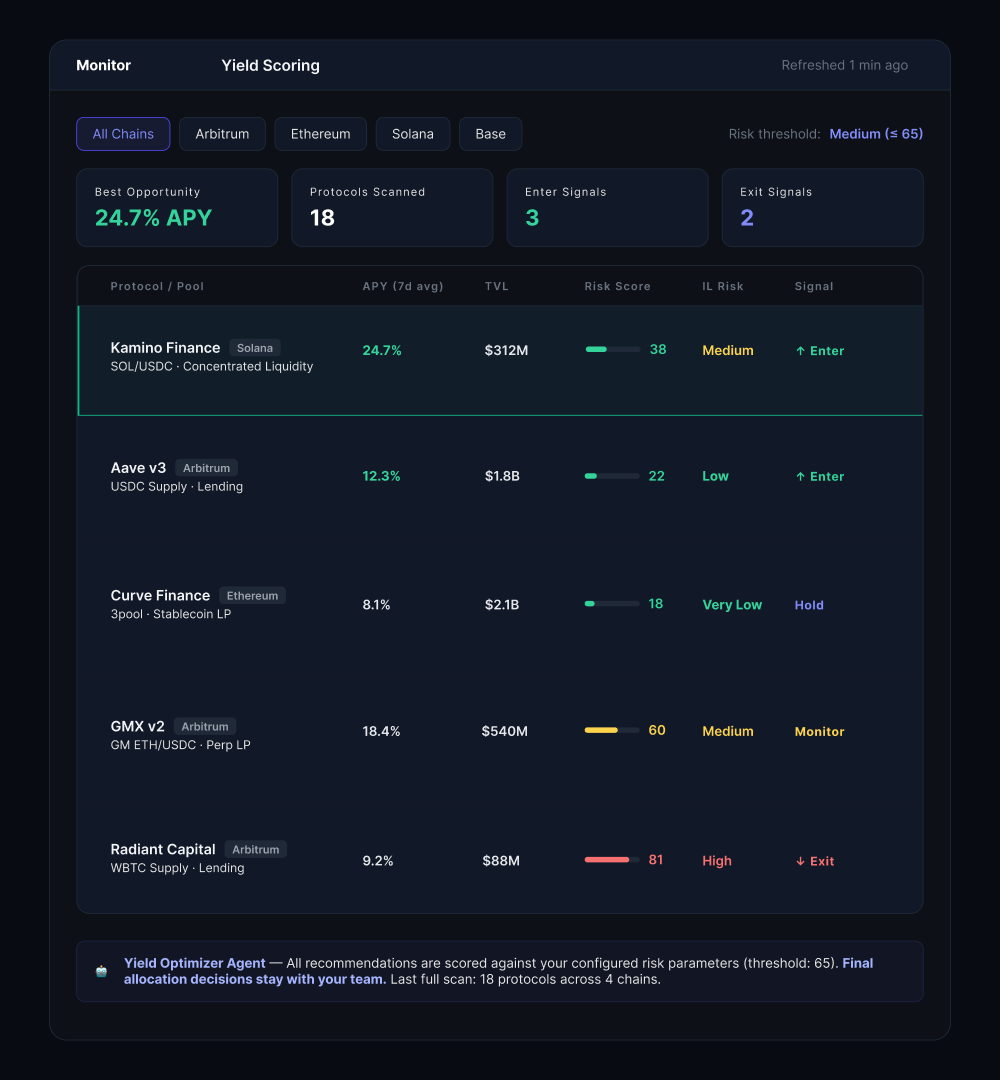
Agent 5 — The morning briefing that used to take hours
The fifth agent consolidates everything into a daily intelligence briefing and handles on-demand reporting.
Before this system, pulling together weekly performance data across four chains and multiple protocols — cross-referencing outputs from tools that don’t share a data model — took the team several hours every week.
Now it generates automatically overnight, structured as an actual decision-making input: executive summary of the previous 24 hours, flagged positions, ranked yield opportunities, risk signals, and performance tracking against strategy parameters. The team comes in the morning with context, not with a task list of data assembly.
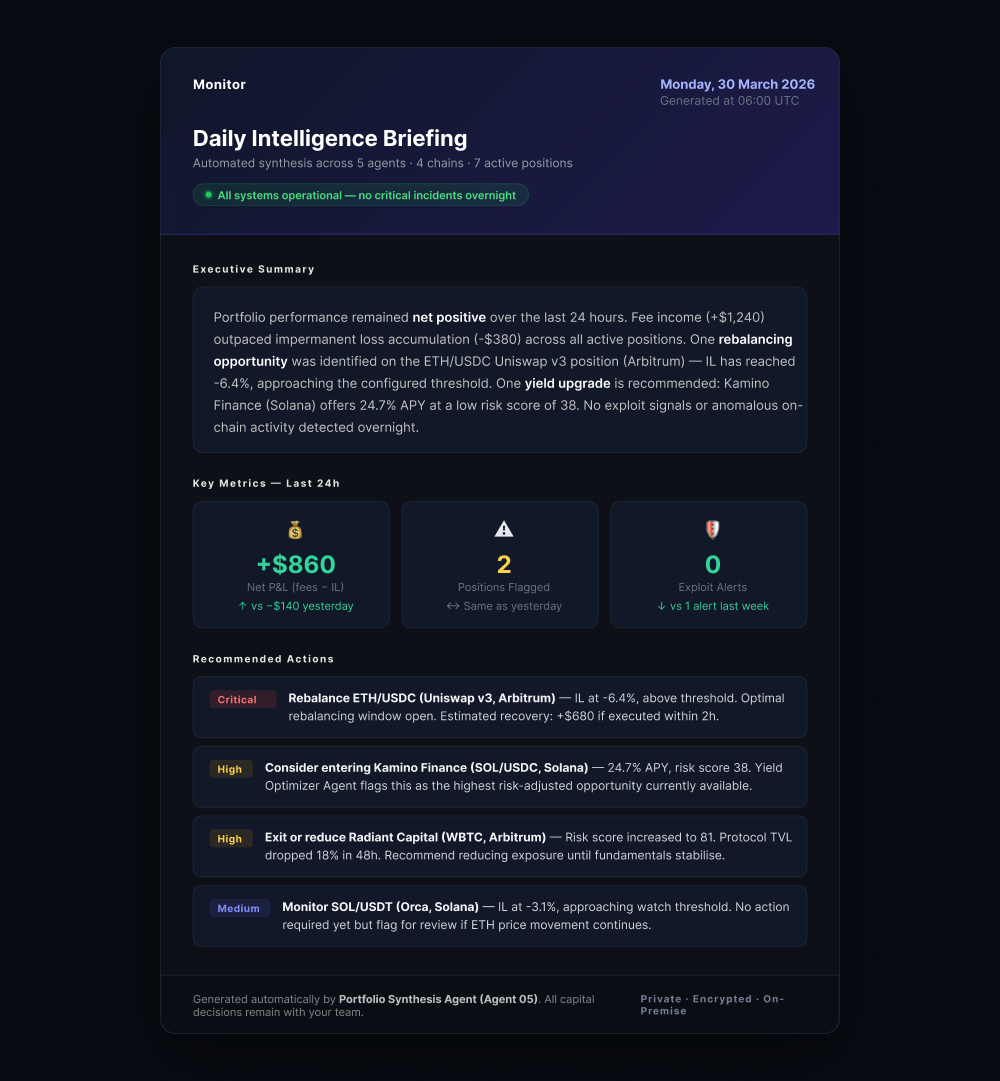
Each interface shown throughout this article corresponds to one of the five agents above. The operator dashboard consolidates agent status, live alerts, and LP position overview into one view — no drilling down required.
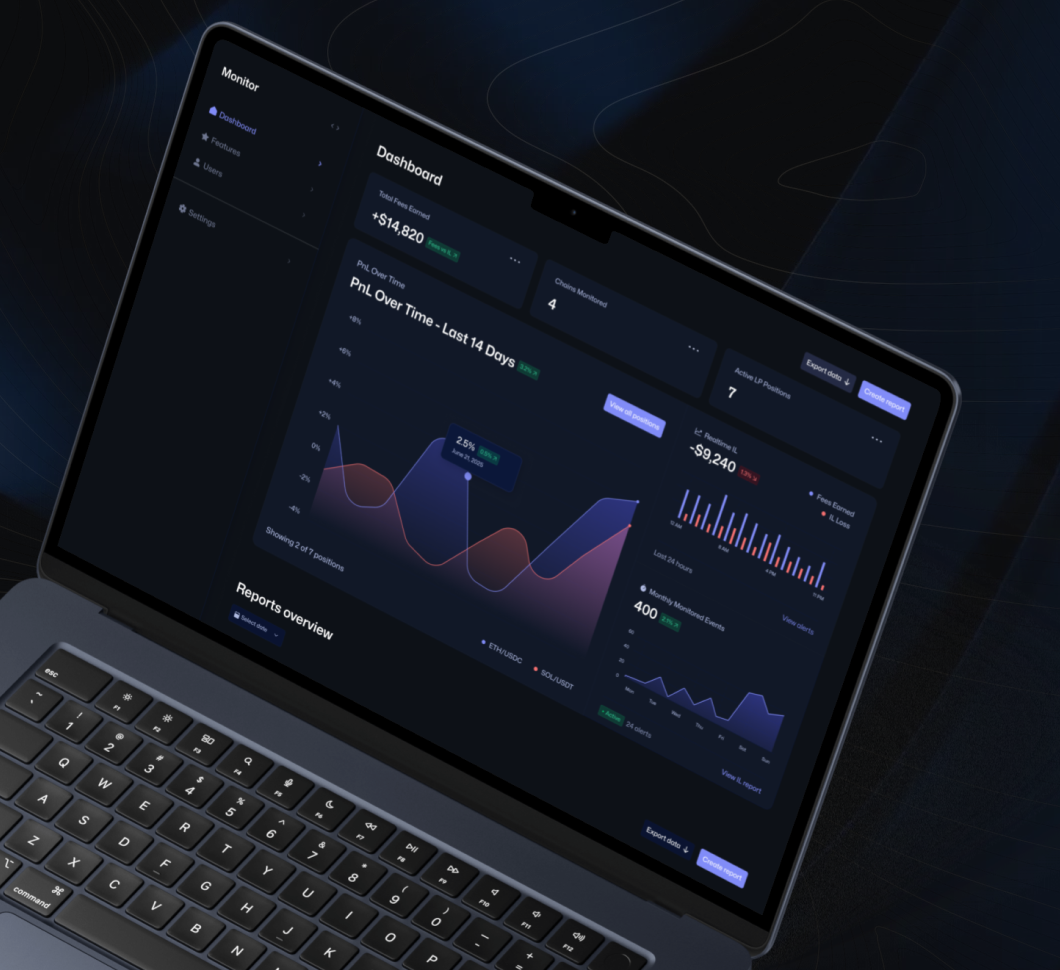
One of the features the team ended up using more than we expected was the risk configuration interface — the no-code panel for adjusting IL thresholds, alert sensitivity, and yield scoring weights without touching code.
DeFi market conditions shift fast — what works in Q1 may need adjustment by Q2, and waiting for an engineering sprint to recalibrate is not a practical option.
They’ve adjusted parameters several times since deployment as conditions shifted. That adaptability turned out to be as valuable as the monitoring itself — a system that was perfectly tuned to Q1 market structure and couldn’t adapt would have become a liability by Q2.
What actually changed
The team moved from isolated, manual tools to a unified system. Now, they monitor and correlate signals across all positions 24/7 — with zero data leaving their infrastructure.
- Rebalancing opportunities that used to pass unnoticed are now flagged in advance. The system now projects the exact dollar value the team stands to gain if they act before the window closes.
- Exploit anomalies surface in seconds rather than in news alerts.
- Weekly reporting that required hours of manual aggregation now generates overnight.
- The yield strategy is scored against live market conditions continuously, not reviewed when someone has time to check.
- Most importantly, faster IL rebalancing allowed fee income to consistently outpace losses — a breakthrough the previous tooling stack couldn’t deliver.
The 4 months it took to build this weren’t straightforward.
The hardest part wasn’t writing the agents – it was the calibration work after first deployment.
Running it on real data, watching what the agents flagged versus what they missed, tightening signal logic, reducing false positives to a level the team actually trusted.
So if someone asks how long something like this takes: 4 months to ship a working system, and then several more weeks of real-data calibration before it’s genuinely sharp.
If you’re managing DeFi positions and your current stack can’t move faster than the market — we should talk.


